
Xã hội
Apple M1: Hãy quên CPU đa dụng đi, giờ là thời của chip xử lý đặc dụng chỉ làm 1 nhiệm vụ

Th12

Trên YouTube, tôi thấy có một anh bạn dùng Mac, mới mua một chiếc iMac vào năm ngoái, trang bị max 40GB RAM, giá khoảng 4.000 USD. Anh này sau đó phải há hốc mồm kinh ngạc vì không thể tin nổi lý do vì sao chiếc máy iMac cực đắt của mình lại có hiệu năng không ăn nổi chiếc Mac mini M1, cái máy mà anh chỉ bỏ ra có 700 USD để sở hữu.
Trong nhiều phép thử tương tự ngoài đời thực, chip M1 không chỉ “tiệm cận” khả năng xử lý của những máy Mac trang bị chip Intel, mà còn đánh bại chúng. Rất nhiều người trên toàn thế giới đều phải đưa ra câu hỏi đầy bất ngờ, nhờ đâu mà điều này lại thành hiện thực được? Nếu bạn là một trong số những người đó, có lẽ bạn đã đến đúng chỗ rồi đấy. Ở đây tôi dự định sẽ giải thích một cách dễ hiểu nhất những gì Apple đã làm với chip M1.
Cụ thể hơn, những câu hỏi rất nhiều người đều đưa ra là:
- Lý do kỹ thuật nào khiến chip M1 nhanh đến như vậy?
- Liệu Apple có đưa ra những lựa chọn kỹ thuật thật sự rất ít người chọn để đem lại hiệu năng đáng nể của chip M1 không?
- Intel và AMD liệu có cửa nào để ứng dụng những mánh như Apple đã làm với chip M1 không?
Dĩ nhiên, những câu hỏi này các bạn hoàn toàn có thể đi search Google, nhưng nếu làm điều này, cố gắng đi tìm những cách giải thích cặn kẽ thay vì những lời giải thích trớt quớt như Apple đã làm, các bạn sẽ nhanh chóng chết chìm trong những thuật ngữ phức tạp, như kiểu chip M1 sử dụng những bộ giải mã lệnh rất rộng, thuật toán sắp xếp lại bộ đệm (ROB) với kích thước khổng lồ,… Trừ phi các bạn là những người mê nghiên cứu kiến trúc CPU, rất dễ bị choáng ngợp bởi những thuật ngữ này.
Thật ra trước khi đọc bài này, có lẽ các bạn nên đọc một bài viết trước của tôi với tiêu đề “RISC và CISC có ý nghĩa gì trong năm 2020?” Trong bài đó, tôi giải thích định nghĩa một chip vi xử lý là gì, cũng như những khái niệm quan trọng như là:
- Kiến trúc tập lệnh – Instruction Set Architecture (ISA)
- Pipelining – Đường ống dữ liệu kết nối theo chuỗi
- Kiến trúc tải/lưu trữ dữ liệu
- So sánh Microcode và Micro-operations
Nhưng nếu không đủ kiên nhẫn đọc lại bài viết đó, thì tôi sẽ viết lại những khái niệm cơ bản để phần nào giải thích dễ hơn cách chip M1 hoạt động.
Chip vi xử lý (CPU) là gì?
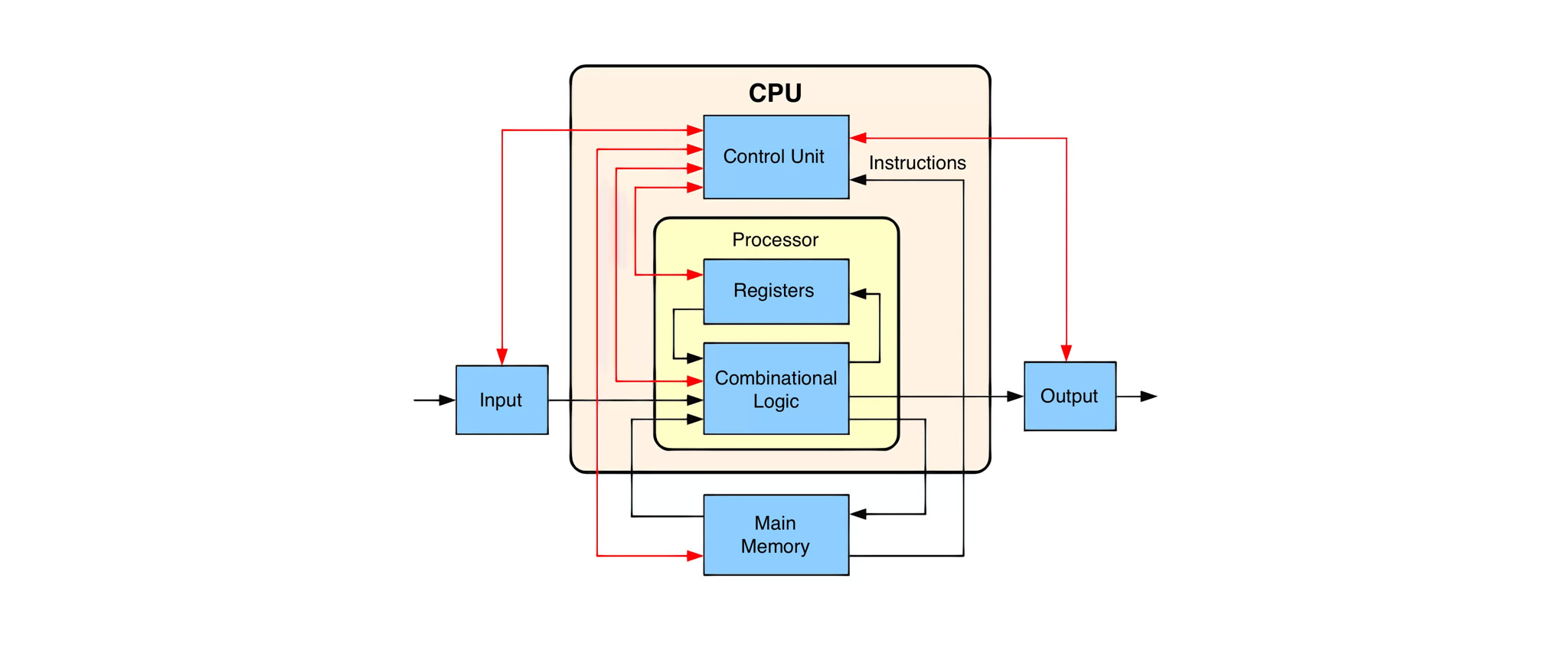
Bình thường, khi nói đến chip do Intel và AMD sản xuất, chúng ta thường chỉ nói đến CPU, hoặc chip vi xử lý. Về cơ bản những chip CPU như thế này lấy hướng dẫn từ bộ nhớ. Sau đó, mỗi lệnh thường được thực hiện theo trình tự trước sau.


Ở đây, r1 và r2 là giá trị trong hai thanh ghi tôi mô tả ở trên. Những CPU RISC hiện đại không thể thực hiện tính toán những con số không được đưa vào thanh ghi như thế này. Lấy ví dụ, nó không tính cộng được hai con số lưu ở hai vị trí khác nhau trong RAM. Thay vào đó, nó phải đưa hai con số này từ bộ nhớ RAM vào thanh ghi trong CPU. Đoạn code trên đây làm đúng nhiệm vụ như thế. Nó tải giá trị r1 ở vị trí 150 trên RAM, và giá trị r2 ở vị trí 200 trên RAM vào instruction register. Chỉ khi ấy, phép tính cộng mới được thực hiện.
Bản chất ý tưởng instruction register cũng đã tồn tại từ rất lâu. Lấy ví dụ như chiếc máy tính cơ học trên đây, register cơ học là thứ lưu trữ giá trị số nguyên bạn dùng để tính toán cộng trừ. Đấy cũng chính là thứ tạo ra khái niệm máy tính tiền (cash register). Thanh ghi là nơi bạn “ghi” giá trị số liệu nhập đầu vào.
Nhưng chip M1 không phải chỉ là một con CPU!
Đến đây chúng ta cần làm rõ một điều rất dễ nhầm lẫn. M1 của Apple không phải là CPU. Nó là cả một hệ thống nhiều con chip bán dẫn xử lý, được nhét vào một gói chip silicon kích thước lớn. CPU chỉ là một phần của toàn bộ con chip M1.
Về cơ bản, M1 là cả một chiếc máy tính trong hình dạng của một chip bán dẫn. Bên trong nó có CPU, có bộ xử lý đồ họa (GPU), bộ nhớ, điều khiển đầu vào và đầu ra, cùng rất nhiều thứ khác hợp thành cả một chiếc máy tính. Khái niệm này được gọi là System on a Chip (SoC).

Hôm nay nếu bạn ra tiệm mua một con chip của Intel hay của AMD sản xuất, bạn sẽ chỉ có được một gói chip bán dẫn bên trong đó có nhiều vi xử lý trong một gói, một con chip cầm trên tay. Trong quá khứ máy tính được trang bị nhiều chip vi xử lý độc lập trên bo mạch chủ. Nhưng nhờ tiến bộ công nghệ, con người có thể tạo ra hàng tỷ transistor trên bề mặt một die chip bán dẫn. Điều này dẫn đến việc Intel và AMD bắt đầu đưa nhiều vi xử lý vào chung một chip. Những vi xử lý trong cùng một con chip đó về sau chúng ta gọi là nhân. Một nhân là một chip vi xử lý độc lập, có thể đọc hướng dẫn từ bộ nhớ để thực hiện ra các phép tính.
Trong một thời gian dài, để tăng hiệu năng xử lý cho máy tính, các hãng chỉ có một chiến lược duy nhất là trang bị càng nhiều nhân vi xử lý trong một chip CPU càng tốt. Nhưng hiện tại xu hướng này đang dần bị xóa bỏ, bời một cái tên duy nhất: Apple.
Chiến lược chip xử lý tính toán không đồng nhất của Apple
Thay vì trang bị nhiều nhân CPU đa dụng cho chip M1, Apple đi theo một chiến lược khác. Họ đưa vào SoC những chip bán dẫn chỉ làm được một số tác vụ đặc biệt riêng. Lợi thế của chiến lược này là những chip bán dẫn đặc biệt thường vận hành để xử lý đúng nhiệm vụ nó được giao với hiệu năng tốt hơn, tiết kiệm điện hơn nhiều so với những vi xử lý đa dụng thông thường.
Đây hoàn toàn không phải kiến thức mới mẻ gì. Trong nhiều năm qua, những chip bán dẫn đặc dụng như GPU đã được trang bị cho những card đồ họa của Nvidia và AMD, xử lý những phép tính liên quan tới đồ họa máy tính nhanh hơn nhiều so với CPU đa dụng. Điều mà Apple đã làm không phải mới mẻ, nhưng lại là hướng đi đột phá theo đúng hướng mà Nvidia và AMD đang làm. Thay vì trang bị cho M1 một số lượng nhân vi xử lý đa dụng, M1 được trang bị rất nhiều chip đặc dụng:
- CPU: “Bộ não” của SoC, đảm nhiệm việc chạy mã lệnh của hệ điều hành cũng như của những ứng dụng anh em đã cài vào máy tính.
- GPU: Xử lý những nhiệm vụ liên quan đến đồ họa, như hiển thị giao diện của một ứng dụng, hoặc xử lý hình ảnh trong game 2D/3D.
- Bộ xử lý hình ảnh (ISP): Dùng để tăng tốc cho những tác vụ thông thường phục vụ cho những ứng dụng xử lý hình ảnh.
- Bộ xử lý tín hiệu số (DSP): Xử lý những phép tính phức tạp hơn, giúp đỡ cho CPU trong quá trình vận hành. Trong những tác vụ cần tới DSP, có thể kể đến việc giải mã những tệp tin nhạc hoặc âm thanh số.
- Bộ xử lý neural (NPU): Dùng trong những smartphone cao cấp, hoặc trong những hệ thống deep learning nghiên cứu trí thông minh nhân tạo. Ở quy mô tiêu dùng, những tác vụ deep learning có thể kể đến cơ chế nhận diện giọng nói hoặc xử lý ảnh chụp.
- Bộ giải mã video: Xử lý một cách tiết kiệm điện những tệp tin video và các định dạng video nói chung.
- Secure Enclave: Xử lý bảo mật.
- Bộ nhớ chung: Cho phép CPU, GPU cùng tất cả những bộ xử lý kể trên trao đổi dữ liệu nhanh chóng.
Đây chính là lý do vì sao những người làm việc trong ngành sáng tạo, xử lý video và ảnh ọt thông qua MacBook M1 lại thấy được hiệu năng tăng đáng kể. Rất nhiều tác vụ họ làm hàng ngày thông qua máy tính được chip M1 xử lý thông qua những bộ xử lý đặc dụng chỉ được tạo ra để hoàn thành một hoặc những nhiệm vụ đặc thù. Đấy chính là lý do, chiếc Mac Mini M1 có thể xử lý một tệp dữ liệu video lớn một cách dễ dàng, trong khi iMac chạy hết công suất cũng không đuổi kịp được hiệu năng.
Kiến trúc bộ nhớ hợp nhất có gì đáng nói?
UMA – Kiến trúc bộ nhớ hợp nhất của Apple khá khó để hiểu ngay những giây đầu tiên Apple giới thiệu về nó. Để hiểu được kiến trúc này, có lẽ phải nhắc lại lịch sử của ngành điện toán.
Trong một thời gian rất dài, những hệ thống máy tính giá rẻ đều có bộ vi xử lý CPU và bộ xử lý đồ họa GPU nằm trên cùng một die chip bán dẫn. Chúng chậm, rất chậm. Trong quá khứ nếu nói “đồ họa tích hợp”, hẳn các bạn cũng hiểu được phần nào hiệu năng của GPU trang bị trong chiếc máy tính đó. Nhưng GPU tích hợp chậm cũng có lý do cả.
Những vùng khác nhau trong bộ nhớ được dành riêng cho CPU và GPU. Nếu CPU có một khoảng dữ liệu nó muốn GPU sử dụng, CPU sẽ không thể nói rằng “đây, dùng tạm một phần bộ nhớ của CPU đi”. Nó sẽ phải copy hết đống dữ liệu đang nằm ở khu vực bộ nhớ dành riêng cho CPU sang khu vực bộ nhớ dành riêng cho GPU để bộ xử lý đồ họa hoạt động.
Cả CPU lẫn CPU đều không muốn bộ nhớ được xử lý theo cùng một cách. Hãy làm một phép so sánh vui và ngốc nghếch. CPU và GPU giống như hai thực khách vào nhà hàng.

Cùng lúc, GPU đòi hỏi một lượng dữ liệu khổng lồ để xử lý song song cùng lúc. Bản chất khác biệt như vậy khiến cho việc đặt cả CPU lẫn GPU vào cùng một die chip bán dẫn chưa bao giờ là ý tưởng hay. Khi CPU nhặt từng mẩu dữ liệu ở tốc độ rất cao, thì GPU sẽ bị bỏ đói. Vì thế, ý tưởng trang bị một chip GPU hiệu suất cao vào SoC cũng là một thử thách không nhỏ đối với các hãng. Dù chỉ là một GPU nhỏ bé yếu đuối, nó vẫn đủ sức “tiêu thụ” một lượng lớn dữ liệu trong bộ nhớ.
Vấn đề thứ hai khi trang bị GPU mạnh vào SoC, đó là chip GPU kích thước lớn, tạo ra rất nhiều nhiệt năng, và sẽ không dễ gì trang bị nó vào chung một die bán dẫn cạnh CPU mà không đưa ra được giải pháp tản nhiệt hiệu quả. Những card đồ họa rời thường trông như hình dưới đây: Kích thước đồ sộ, với cả quạt lẫn heatsink. Chúng có cả bộ nhớ riêng rẽ để phục vụ cho chip GPU tham lam trang bị bên trong.

Đó là lý do vì sao card đồ họa rời lại mạnh đến vậy. Nhưng nó cũng có điểm yếu, cũng có “gót chân Achilles” riêng: Mỗi lần muốn lấy dữ liệu từ bộ nhớ dành riêng cho CPU, linh kiện PC phải làm điều này thông qua những con đường lát gạch đồng trên bo mạch chủ của máy tính, gọi là PCIe lane. Thử tưởng tượng uống nước bằng một cái ống hút rất nhỏ, hút thì nhanh nhưng chẳng được bao nhiêu.
Điều đó đưa chúng ta đến với kiến trúc Unified Memory Architecture của Apple. UMA cố gắng giải quyết tất cả những vấn đề kể trên, mà không có bất kỳ bất lợi nào liên quan đến giải pháp chia sẻ bộ nhớ giữa CPU và GPU theo kiểu cũ. Để làm được điều này, Apple đã thiết kế lại kiến trúc bộ nhớ theo những hướng sau:
- Không có khu vực bộ nhớ riêng phục vụ CPU hoặc GPU. Bộ nhớ dùng chung cho cả hai chip xử lý. Cả hai chip đều có thể dùng những khu vực bất kỳ trong chip RAM, vì thế không cần phải copy dữ liệu như trước nữa.
- Apple sử dụng những chip RAM cho phép điều chuyển lượng dữ liệu khổng lồ trong thời gian cực ngắn. Nói theo kiểu khoa học máy tính thì khả năng đó gọi là độ trễ thấp và băng thông cao. Vì thế nhu cầu trang bị những loại bộ nhớ khác nhau cho CPU và GPU không còn nữa.
- Apple kiểm soát điện năng GPU sử dụng, vì thế GPU hiệu năng cao vẫn có thể trang bị vào SoC mà không khiến toàn bộ hệ thống quá tải nhiệt.

Cũng đúng, vì trước kia cũng đã có những hệ thống sử dụng bộ nhớ chung. Nhưng thời đó, khác biệt về nhu cầu sử dụng bộ nhớ giữa CPU và GPU không khác biệt quá lớn như bây giờ. Nvidia cũng từng nói về “bộ nhớ hợp nhất”, nhưng ý tưởng của họ hoàn toàn không giống UMA của Apple. Đối với Nvidia, để tạo ra bộ nhớ hợp nhất, sẽ cần tới cả phần cứng lẫn phần mềm đảm nhiệm tác vụ tự động điều chuyển dữ liệu từ các phân vùng phục vụ cho CPU và GPU qua lại lẫn nhau. Ý tưởng “unified memory” của Nvidia và Apple đều được đưa ra để đạt chung một mục đích, nhưng về mặt bản chất xử lý, chúng khác nhau hoàn toàn.

Dĩ nhiên, chiến lược của Apple vẫn sẽ phải đánh đổi một vài thứ. Quan trọng hơn cả là, để sử dụng bộ nhớ chung với tốc độ và băng thông cực cao như vậy, Apple sẽ phải tích hợp hoàn toàn bộ nhớ vào SoC, đồng nghĩa với việc anh em sẽ không thể nâng cấp RAM cho máy Mac như trước kia nữa.
Nhưng bù lại, Apple muốn phần nào giảm thiểu tác động của việc không thể nâng cấp RAM bằng cách cho phép chip M1 tương tác với SSD ở tốc độ rất cao, cao tới mức SSD có thể trở thành bộ nhớ cho cả hệ thống máy tính.
Nếu SoC ngon thế, sao Intel và AMD không bắt chước?
Thật ra không riêng gì Apple, nhiều nhà sản xuất chip sử dụng kiến trúc ARM hay x86 trên thế giới cũng đã và đang tối ưu những phần cứng đặc dụng vào chung một die chip bán dẫn. Từ Snapdragon, Exynos cho đến Kirin, tất cả đều có CPU, GPU, ISP, DSP hay NPU kết hợp trong cùng một SoC, nhưng hầu hết đều được trang bị cho smartphone chứ chưa có nhiều sản phẩm đặc thù cho laptop hoặc desktop PC. Về phần AMD, trong nhiều năm qua, họ cũng có những mẫu APU trang bị tích hợp cả CPU lẫn GPU, với nhân GPU hiệu năng cao đủ để chơi game. Đấy cũng là một dạng SoC với nhiều chip xử lý trong cùng một die bán dẫn.

Nhưng có một lý do rất quan trọng khiến cho AMD, Intel hay những hãng khác không làm được điều như Apple. SoC là cả một hệ thống máy tính chỉ trong một con chip bán dẫn. Những sản phẩm như thế trở nên hợp lý hơn trong mắt những nhà sản xuất máy tính, ra mắt sản phẩm trọn gói, như PC của Dell, HP, hay chính bản thân Apple. Nếu mô hình kinh doanh đang chỉ dừng lại ở việc sản xuất và bán chip xử lý, thì việc chuyển sang sản xuất cả hệ thống máy tính hoàn chỉnh sẽ không mấy hợp lý.
Trong khi đó đối với ARM, đó hoàn toàn không phải vấn đề. Những hãng máy tính hoàn toàn có thể mua bản quyền thiết kế kiến trúc chip bán dẫn của ARM, rồi mua tài sản trí tuệ để sản xuất những chip khác, để đưa vào SoC của họ bất kỳ chip đặc dụng nào họ muốn, như Apple đã làm với M1. Tiếp theo, họ giao hợp đồng cho những đơn vị fab chip bán dẫn như TSMC, Samsung hay GlobalFoundries, cũng là những bên đang sản xuất chip cho Apple, AMD hay Nvidia.

Quay trở lại với mô hình kinh doanh của Intel và AMD. Họ làm giàu bằng cách bán ra thị trường những chip CPU đa dụng, mua về phải mua thêm bo mạch chủ để lắp vào, rồi đến RAM và SSD hay thậm chí cả GPU rời để khởi động máy tính. Đấy cũng là giải pháp nhiều hãng máy tính đang triển khai, mua linh kiện từ nhiều nguồn rồi ráp chúng thành một hệ thống hoàn chỉnh để bán ra thị trường.
Nhưng chúng ta có lẽ đang rời xa thế giới PC hoạt động theo mô hình như vậy. Trong thế giới mới của những SoC, bạn sẽ không còn cần phải tìm từng linh kiện khác nhau từ các hãng khác nhau nữa. Thay vào đó, các hãng sẽ “lắp ráp” các tài sản trí tuệ của các đơn vị khác mà họ đã mua. Họ sẽ mua thiết kế GPU, CPU, modem, IO controller và những thứ khác để tự tạo ra một SoC in-house. Rồi sau đó chỉ cần tìm foundry để sản xuất ra con chip đps.
Đến đây chúng ta sẽ có một vấn đề lớn, vì Intel, AMD hay Nvidia đều sẽ không chịu bán tài sản trí tuệ cho Dell hay HP để cho phép họ tự sản xuất SoC trang bị trong các hệ thống desktop hay laptop đóng mác Dell và HP.
Sẽ đến lúc, Intel hay AMD sẽ đơn giản là bắt đầu thiết kế, sản xuất và bán ra thị trường những SoC hoàn thiện. Nhưng bên trong những SoC đó liệu sẽ có những linh kiện và chip đặc dụng nào? Mỗi nhà sản xuất PC đều có ý tưởng và nhu cầu riêng về những linh kiện bên trong một SoC. Sẽ tới lúc Intel và AMD xuất hiện ra những bất đồng với không chỉ các nhà sản xuất PC mà còn với cả Microsoft, về việc trong một SoC cần có những bộ phận nào cấu thành.
Còn đối với Apple, chuyện rất đơn giản. Họ chỉ cần kiểm soát toàn bộ hệ thống, từ phần cứng tới phần mềm. Lấy ví dụ họ đem đến cho các lập trình viên thư viện Core ML để phát triển những hệ thống machine learning. CoreML chạy trên CPU, hay trên chip xử lý neural, điều đó các dev không cần quan tâm.
Thử thách cơ bản khi tạo ra một CPU hiệu năng cao
Một trong những lý do khiến CPU không có hiệu năng cao ở tất cả mọi tác vụ khác nhau là vì cơ chế tính toán không đồng nhất (heterogeneous computing). Nhưng đó không phải nguyên nhân duy nhất. Bốn nhân CPU hiệu năng cao trong chip M1, tên là Firestorm, thực sự có tốc độ đáng nể. Con số benchmark những máy Mac trang bị chip M1 khác biệt rất lớn so với những nhân CPU ARM ra mắt trước đó, vốn rất yếu nếu so sánh với CPU của Intel hay AMD.
Firestorm, trái lại, đánh bại hầu hết những CPU Intel và suýt chút nữa đánh bại luôn cả CPU mạnh nhất của AMD Ryzen. Trước khi nói về lý do vì sao Firestorm lại mạnh đến như vậy, chúng ta phải hiểu được giải pháp cơ bản để giúp một nhân vi xử lý tăng hiệu năng làm việc.
Về cơ bản, để tạo ra một nhân CPU mạnh, các nhà sản xuất phải cùng lúc hoàn thành hai chiến lược:

Hồi những năm 80 của thế kỷ trước, chuyện này thì đơn giản. Chỉ cần tăng xung nhịp và chuỗi lệnh sẽ hoàn thành nhanh hơn. Mỗi chu kỳ xung nhịp là khoảng thời gian máy tính hoàn thành một tác vụ. Nhưng “tác vụ” này có thể lớn, cũng có thể nhỏ. Vì thế một instruction có thể cần nhiều chu kỳ để hoàn thành, vì nó được cấu thành từ nhiều tác vụ nhỏ. Nhưng đến giờ, tăng xung nhịp gần như không còn khả thi nữa. Đấy là lúc, ai cũng lên tiếng nói rằng “định luật Moore đã chết” như trong vài năm nay.
Và giải pháp để tăng hiệu năng CPU giờ chỉ còn một cách, đó là làm cách nào xử lý cùng lúc càng nhiều instruction càng tốt.
Chọn CPU Multi-core hay Out-of-Order bây giờ?
Có hai hướng tiếp cận vấn đề, để tăng tốc xử lý một instruction cho CPU. Một là trang bị thêm nhiều nhân CPU. Trên phương diện người lập trình, điều này đồng nghĩa với việc thêm vào nhiều luồng xử lý phục vụ song song nhiều tác vụ cùng lúc. Mỗi nhân CPU là một luồng phần cứng xử lý. Để cho dễ hiểu, những “luồng” này có thể coi là quá trình xử lý một tác vụ cụ thể. Với CPU 2 nhân, nó có thể xử lý đồng thời song song hai tác vụ cùng lúc (2 luồng). Hai tác vụ đó có thể coi là hai “chương trình” độc lập lưu trong bộ nhớ, hoặc nó có thể là một chương trình được xử lý hai lần. Mỗi luồng xử lý cần kiểm soát dữ liệu, ví dụ như chuỗi lệnh hướng dẫn cho luồng xử lý đang ở đâu trong bộ nhớ. Mỗi luồng cũng sẽ cần chỗ lưu dữ liệu tạm thời một cách độc lập.
Trên nguyên tắc, một vi xử lý có thể chỉ cần một nhân và chạy nhiều luồng xử lý. Trong trường hợp này, nhân xử lý sẽ tạm thời ngừng làm việc một luồng tác vụ, lưu tạm kết quả dang dở trước khi chuyển sang luồng tác vụ khác, xong thì quay lại làm nốt tác vụ đang dở. Xử lý theo kiểu này thực tế không khiến hiệu năng tăng lên, và chỉ được sử dụng khi một luồng xử lý thường xuyên bị ngừng lại để chờ lệnh từ người dùng, chờ dữ liệu trong trường hợp kết nối tốc độ chậm, v.v… Đây là luồng xử lý phần mềm. Luồng xử lý phần cứng đồng nghĩa với việc bạn sẽ có thêm những phần cứng vật lý, như thêm nhân xử lý để tăng tốc độ làm việc với máy tính.
Vấn đề với nhiều luồng xử lý phần cứng là lập trình viên sẽ phải viết phần mềm để tối ưu khả năng xử lý của nhiều nhân CPU cùng lúc. Một vài tác vụ như phần mềm máy chủ rất dễ viết theo kiểu này. Những tác vụ xử lý qua máy chủ gần như độc lập với nhau, khi ấy CPU máy chủ càng nhiều nhân thì càng xử lý được cho nhiều người dùng. Ấy vậy nên những chiếc như Xeon hay Threadripper là lựa chọn tuyệt vời cho những dịch vụ điện toán đám mây.

Dựa trên kiến trúc ARM, các nhà sản xuất chip bán dẫn cũng có những mẫu CPU điên rồ, như Altra Max của Ampere với 128 nhân xử lý. Nó được phát triển chỉ để phục vụ cho ứng dụng điện toán đám mây. Đối với ngành này, hiệu năng đơn nhân điên rồ không quan trọng bằng tỷ lệ giữa số luồng xử lý song song và điện năng tiêu thụ, để phục vụ càng nhiều người dùng càng tốt.
Apple, trái lại, nằm ở thái cực hoàn toàn ngược lại so với những nhà sản xuất CPU phục vụ máy chủ đám mây. Apple sản xuất thiết bị tiêu dùng cho người dùng đầu cuối. Nhiều nhân, rất nhiều nhân xử lý không phải lợi thế quan trọng nhất. Thiết bị của họ dùng để xử lý hình ảnh, video, phát triển phần mềm… Họ muốn máy tính của mình sở hữu những hình họa và chi tiết đồ họa đẹp nhất có thể.
Thêm nữa, phần mềm máy tính cá nhân thường không được tối ưu cho hàng chục, hàng trăm nhân xử lý đồng thời. Một trong những tác vụ nặng nhất đối với máy tính hiện tại là chơi game, nó có thể tối ưu tốt cho những CPU 8 nhân, nhưng 128 nhân thì chưa chắc, dùng CPU ấy chơi game quá phí. Đối với máy tính cá nhân, các bạn sẽ cần những nhân CPU mạnh hơn, nhưng số lượng nhân ít hơn máy chủ nhiều.
Điều thú vị là, xử lý tác vụ theo kiểu không có trật tự (Out-of-Order – OoO) là một cách để CPU xử lý nhiều lệnh hơn cùng một lúc, mà không cần đến nhiều luồng xử lý. Các lập trình viên cũng không cần viết phần mềm để tự tối ưu cho cách xử lý OoO. Nhìn từ góc nhìn của lập trình viên, chỉ cần hiểu đơn giản là mỗi nhân CPU chạy nhanh hơn mà thôi.

Để hiểu hơn về Out-of-Order, cũng cần hiểu vài thứ về cách bộ nhớ máy tính vận hành. Xin dữ liệu từ một phân vùng cụ thể trong bộ nhớ rất chậm. Nhưng vấn đề là xin 1 byte dữ liệu từ RAM vào CPU, thì thời gian trả về và độ trễ cũng nhanh y hệt như khi xin 128 bytes dữ liệu. Chúng được gửi qua lại CPU và RAM thông qua một thứ gọi là databus, một đường hầm giữa bộ nhớ RAM và những phần khác nhau trong một chip CPU, nơi dữ liệu được gửi qua gửi lại. Trên thực tế thì “đường hầm” này chỉ là những đường mạ đồng chằng chịt trên bo mạch chủ của anh em, có khả năng dẫn điện. Databus càng “rộng”, thì lượng dữ liệu gửi được cùng lúc cũng càng nhiều.
CPU khi ấy nhận được một loạt những instruction để xử lý cùng lúc. Nhưng chúng được lập trình để thực hiện lần lượt. Còn những vi xử lý hiện đại thì có một khả năng gọi là xử lý không theo trình tự, Out-of-Order.
Điều này đồng nghĩa với việc các CPU có thể phân tích một lượng instruction rất nhanh và định hình xem phép tính nào liên quan tới nhau. Ví dụ:
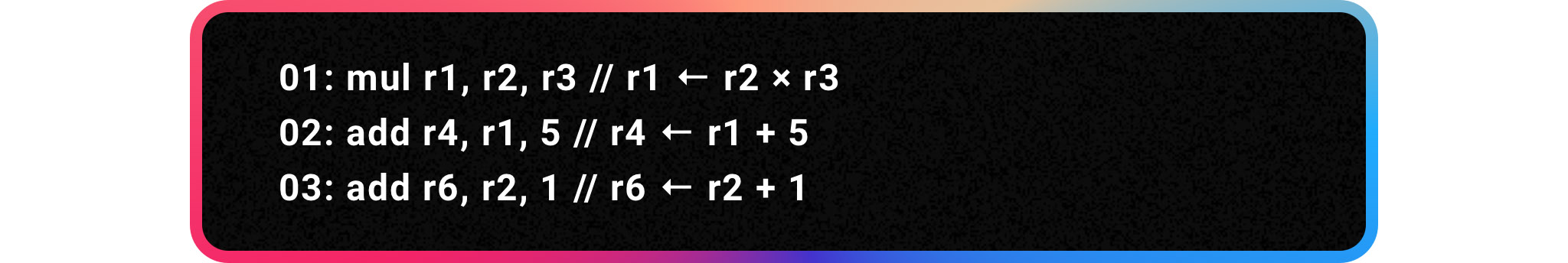
Phép nhân xử lý luôn chậm hơn phép cộng. Hãy cứ lấy ví dụ phép nhân cần nhiều chu kỳ xung nhịp để hoàn thành. Phép tính thứ hai tính giá trị r4 sẽ phải chờ đợi vì nó cần kết quả r1 của phép tính thứ nhất. Tuy nhiên phép tính thứ 3 không phụ thuộc vào cả hai phép tính trước đó. Vì thế với cơ chế Out-of-Order, CPU sẽ có thể bắt đầu tính toán phép tính thứ 3, tìm ra giá trị r6 cùng lúc với phép tính đầu tiên.
Lấy ví dụ cho vui vậy thôi, chứ CPU hiện đại giờ có thể thực hiện hàng tỷ tỷ phép tính như thế mỗi giây, mỗi chu kỳ xung nhịp có thể xử lý hàng trăm hàng nghìn instruction lần lượt, và cũng biết tương quan giữa từng phép tính xem instruction nào liên quan tới nhau. Lấy ví dụ, lệnh add r4, r1, 5 phụ thuộc vào dữ liệu r1, tạo ra từ phép tính mul r1, r2, r3. Lập trình viên có thể đưa hai phép tính này vào một bảng tính để CPU làm việc từ từ.
Nhiều phép tính có thể hoàn thành sớm nhưng không thể lấy kết quả làm giá trị chính thức. Chúng được đưa xuống tầng dưới trong chuỗi instruction CPU phải xử lý. Vi xử lý sẽ cứ tiếp tục thực hiện lần lượt những tác vụ theo thứ tự, tác vụ nào chưa đạt giá trị thỏa mãn thì cho xuống dưới, nhường chỗ cho tác vụ mới làm việc, tất cả chỉ hoàn thành khi tất cả các phép tính đều được giải quyết xong.
Giải thích thì ngắn gọn, nhưng đó là nền tảng của cơ chế xử lý Out-of-Order. Về cơ bản thành quả sẽ trông giống như CPU chỉ cần 1 luồng xử lý tất cả mọi công việc, còn đối với lập trình viên, Out-of-Order cho phép họ ứng dụng những tác vụ song song xử lý rất nhanh.
Và cũng chính nhờ đó, nhân CPU Firestorm trong chip M1 của Apple mới có được hiệu năng đáng nể như vậy. Về cơ bản nó khỏe hơn gần như tất cả những sản phẩm tiêu dùng từ phía Intel và AMD, không cần bàn đến những đối thủ khác trên thị trường chip bán dẫn.
Vì sao khả năng xử lý Out-of-Order của CPU Intel và AMD kém hơn Apple M1?
Ở trên, phần giải thích cách mà giải pháp Out-of-Order execution hoạt động, vẫn thiếu vài điều quan trọng cần đề cập để giải thích thêm cho sức mạnh của CPU Firestorm trong chip M1 của Apple. Những lý do đó có thể giải thích vì sao Intel và AMD khó có thể vượt qua được hiệu năng của chip M1.
Có một khái niệm gọi là Reorder Buffer (Bộ nhớ đệm sắp xếp lại – ROB), và phần này không chứa những hướng dẫn xử lý tác vụ thông thường. Nó không phải thứ CPU lấy từ bộ nhớ để xử lý. Chúng là những instruction bên trong kiến trúc tập lệnh (ISA – Instruction Set Architecture). Đó chính là những kiến trúc mà chúng ta gọi tên là x86, là ARM hay PowerPC.
Tuy nhiên, CPU vận hành dựa trên một bộ kiến trúc tập lệnh hoàn toàn độc lập, được gọi là micro-operations (micro-ops hoặc μops). ROB chứa đầy những tập lệnh nhỏ như vậy. Các tập lệnh này rất rộng, và có thể chứa nhiều dạng siêu thông tin khác nhau. Bạn sẽ không thể thêm những dạng thông tin như thế vào kiến trúc tập lệnh ARM hay x86, vì một trong vài hậu quả dưới đây sẽ xảy ra:
- Nó có thể khiến chương trình nhị phân phình ra đáng kể
- Để lộ chi tiết về cách CPU vận hành, liệu nó có hỗ trợ Out-of-Order hay không, có cho phép đổi tên thanh ghi hay không, hay nhiều chi tiết khác.
- Rất nhiều dạng siêu thông tin chỉ có giá trị trong ngữ cảnh xử lý ở đúng thời điểm đó.
Dễ hiểu hơn, ARM, x86 hay PowerPC giống như những bộ API công khai, còn micro-ops là bộ API riêng tư để các kiến trúc tập lệnh kể trên vận hành hiệu quả. Thêm nữa, micro-ops cũng cho phép CPU vận hành dễ dàng hơn, vì mỗi operation trong đó chỉ thực hiện một tác vụ đơn giản. Những tập lệnh ISA thông thường có thể trở nên vô cùng phức tạp, khiến nhiều thứ ngoài ý muốn xảy ra, vì thế chúng được dịch thành nhiều micro-ops nhỏ khác nhau.
Đối với những CPU CISC, gần như không có cách nào khác ngoài việc phải làm việc với những micro-ops đó, nếu không những tập lệnh phức tạp của kiến trúc CISC sẽ tạo ra đường hầm cố định cho các tác vụ, khiến việc xử lý thông qua giải pháp Out-of-Order gần như bất khả thi. Trong khi đó, những CPU kiến trúc RISC lại có lựa chọn riêng. Ví dụ những CPU ARM nhỏ gần như không dùng micro-ops, và cũng đồng nghĩa với việc không thể ứng dụng Out-of-Order.
Những dòng khó hiểu ở trên thì có ý nghĩa gì khi so sánh Intel và AMD với Apple M1?
Lý do rất đơn giản, hiệu năng của CPU nhanh đến đâu, hoàn toàn phụ thuộc vào tốc độ lấp đầy bộ nhớ đệm ROB, và lấp đầy chúng với bao nhiêu lệnh tính toán micro-ops. ROB ghi dữ liệu càng nhanh, càng nhiều, thì cơ hội để CPU “nhặt” ra những tập lệnh để xử lý song song cũng cao hơn, dẫn đến một hệ quả đơn giản mà ai cũng muốn: Hiệu năng xử lý tăng.

Đó cũng là điểm khác biệt lớn giữa Apple M1 so với bất kỳ CPU nào của Intel và AMD. Những con chip CPU khủng nhất của Intel và AMD cùng lắm cũng chỉ có 4 decoder, nghĩa là cùng lúc có thể dịch 4 tập lệnh trở thành micro-ops để CPU xử lý. Còn M1 thì có đến 8 decoder, còn kích thước ROB thì lớn hơn đến 3 lần. Hiểu đơn giản, bạn có thể lưu gấp 3 lần số tập lệnh để CPU làm việc. Không có một con chip xử lý nào trên thị trường hiện giờ có ngần ấy decoder cả.
Vậy tại sao Intel và AMD không cho thêm decoder dịch tập lệnh vào CPU của họ?
Đây là lúc chúng ta được thấy kiến trúc RISC trỗi dậy trả thù CISC, với nhân CPU Firestorm trong SoC M1. Một tập lệnh x86 có thể dài từ 1 đến 15 bytes. Trên kiến trúc RISC, kích thước tập lệnh là cố định. Khi ấy, bẻ gãy một lượng dữ liệu thành những tập lệnh và gửi vào 8 “máy dịch” trong CPU của chip M1 cùng lúc trở nên đơn giản vô cùng, khi mỗi tập lệnh đều có độ dài như nhau. Tuy nhiên trên CPU x86, decoder hoàn toàn không biết tập lệnh kế tiếp bắt đầu từ đâu. Nó phải phân tích cụ thể từng tập lệnh để biết chúng dài cỡ nào.
CPU của Intel và AMD xử lý bước này đúng kiểu “bạo lực”, khi chúng cố gắng dịch tập lệnh ở mọi điểm khởi đầu có thể. Điều đó đồng nghĩa với khả năng phải đối mặt với rất nhiều lần CPU đoán sai, hay những lỗi cơ bản khiến quá trình decode instruction phải bỏ đi làm lại. Điều này tạo ra giai đoạn dịch tập lệnh vô cùng phức tạp và rối như canh hẹ, cùng lúc rất khó đưa nhiều decoder vào CPU để song song xử lý. Còn đối với Apple, những điều đó không xảy ra, nên cứ thêm decoder vào CPU là làm việc mặc định nhanh hơn.
Thực tế đối với kiến trúc x86, thêm quá 4 decoder tạo ra quá nhiều vấn đề phiền toái, đến mức theo chính lời của AMD, con số 4 là lượng decoder tối đa có thể trang bị trong một CPU. Đó chính là một phần lý do giúp cho Firestorm trong M1 xử lý gấp đôi lượng tập lệnh cùng lúc so với CPU Intel và AMD vận hành ở cùng xung nhịp.
Sẽ có nguời cho rằng, tập lệnh của kiến trúc CISC được dịch ra làm nhiều micro-ops, mật độ dày hơn nên giải mã một tập lệnh x86 cũng giống như giải mã 2 tập lệnh ARM. Vấn đề là ngoài đời thực, “lý thuyết” kiểu này không đúng lắm. Những dòng lệnh x86 được tối ưu tốt hiếm khi dùng những tập lệnh CISC phức tạp, mà thậm chí đôi khi chúng đơn giản hệt như RISC. Dù vậy, CPU của Intel lẫn AMD đều phải được thiết kế decoder để xử lý những tập lệnh phức tạp và dài nhất, ở ngưỡng 15 bytes, dù không phải tập lệnh nào cũng phức tạp như vậy. Chính vì cái chuỗi nguyên nhân hệ quả như vậy, CPU của Intel và AMD không được trang bị quá 4 decoder để vận hành.
Nhưng mà Zen 3 của AMD hiện giờ vẫn nhanh hơn Firestorm của M1 đúng không?
Đúng, nhưng để đổi lại hiệu năng nhanh hơn chip M1, nhân CPU của chip kiến trúc Zen 3 từ AMD phải vận hành ở xung nhịp 5 GHz, còn Firestorm trong M1 chỉ chạy ở xung nhịp 3.2 GHz mà thôi. Xung nhịp nhanh hơn 60%, nhưng hiệu năng benchmark của CPU Ryzen kiến trúc Zen 3 chỉ nhỉnh hơn SoC M1 một chút.
Vậy tại sao Apple không tăng luôn xung nhịp của 4 nhân CPU Firestorm để đánh bại AMD luôn cho tiện? Vì nếu làm thế, hệ thống tản nhiệt sẽ phải gánh nguồn nhiệt năng khổng lồ mà con chip tạo ra. Đấy cũng chính là một phần lợi thế mà Apple không ngần ngại khoe khoang. Máy tính của Apple, không như những cỗ máy trang bị CPU Intel hay AMD, gần như không cần quạt tản nhiệt. Nếu muốn hiệu năng tăng lên, Apple sẽ tăng lượng nhân CPU hiệu năng cao, thay vì nâng xung nhịp của chip. Nhờ đó, điện năng sử dụng sẽ được giữ ở mức lý tưởng, trong khi hiệu năng thì vẫn cứ tăng.
Tương lai của AMD và Intel
Có vẻ như, cả Intel lẫn AMD đều đang tự đẩy họ vào lối cụt ở hai khía cạnh:

Dĩ nhiên điều này không đồng nghĩa với việc “trò chơi kết thúc” với Intel hay AMD. Họ dĩ nhiên vẫn có thể đẩy xung nhịp lên cao hơn nữa, làm mát CPU tốt hơn, trang bị nhiều nhân hơn, tăng bộ nhớ đệm cho CPU, v.v… Nhưng cả hai cái tên này đều đang gặp bất lợi. Intel thì đang ở tình thế tồi tệ hơn, khi nhân CPU họ tạo ra đã không đọ lại được Firestorm trong chip M1, đã thế GPU lại chưa đủ mạnh để trang bị cho một hệ thống SoC đòi hỏi hiệu năng cao.
Vấn đề của việc trang bị nhiều nhân vi xử lý trong một con chip CPU là đối với những tác vụ thông thường của người dùng đầu cuối, lợi ích sẽ giảm dần khi có quá nhiều nhân, không bù lại được so với chi phí bỏ ra. Dĩ nhiên những chip 64 hay 128 nhân vẫn quá tuyệt cho mục đích vận hành máy chủ đám mây. Nhưng cùng lúc, những tập đoàn như Amazon hay Ampere cũng đang tấn công mô hình kinh doanh của Intel với những CPU quái vật trang bị 128 nhân.

May mắn thay cho cả AMD lẫn Intel, Apple chỉ sản xuất chip M1 phục vụ cho nhu cầu “tự sản tự tiêu”, không bán nó ra thị trường. Vì thế thị trường PC về cơ bản vẫn sẽ phải chung sống với những sản phẩm AMD và Intel ra mắt hàng năm. Sẽ có người dùng PC nhảy tàu sang Mac, nhưng quá trình đó sẽ diễn ra rất chậm. Người dùng sẽ không đành lòng từ bỏ một nền tảng mà họ đã đầu tư quá nhiều tiền để đổi sang một nền tảng khác.
Nhưng đối với những người làm việc chuyên nghiệp, có tiền để đầu tư, và bị gắn bó quá mật thiết vào một trong hai nền tảng PC và Mac, họ sẽ có thể chọn giải pháp Apple nhiều hơn trong tương lai, từ đó giúp Apple tăng thị phần người dùng chuyên nghiệp hoặc thiết bị cao cấp, và dần dà là cả thị trường PC nói chung.
Theo medium/Erik Engheim